Now that you can meter usage, you can price it like an adult.
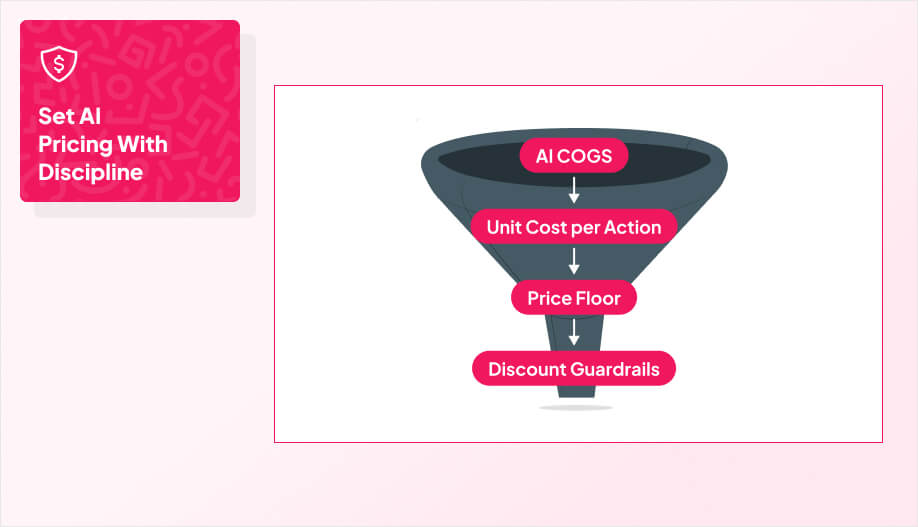
The job here is simple: map pricing to value while protecting margin. AI-first products carry variable costs that scale with usage, so if your pricing ignores that, you’ll feel it the moment a few power users show up. At the same time, if your pricing feels unpredictable or confusing, customers won’t trust it, even if it’s technically “fair.”
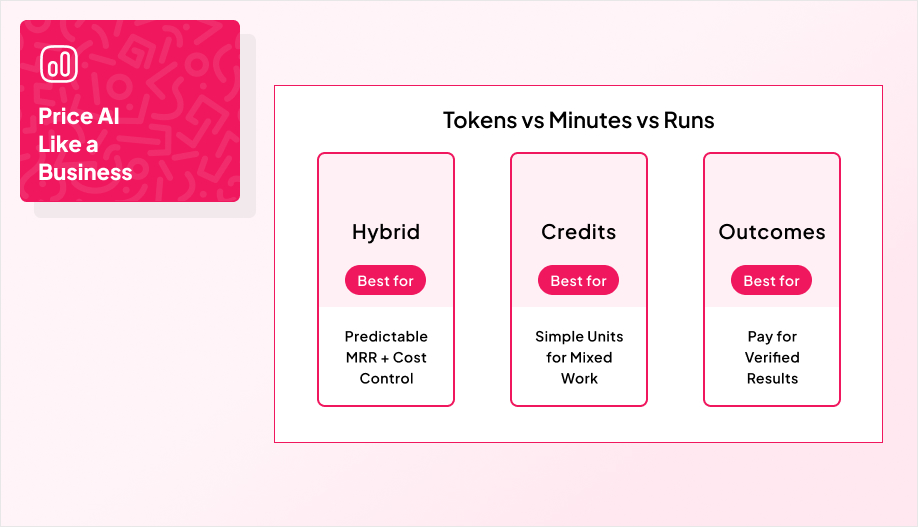
Most teams land on one of three models, depending on how predictable the usage is and how measurable the value is:
- Hybrid subscription + usage when you want predictable MRR but still need a pressure-release valve for heavy consumption.
- Credits and wallets when you want one customer-friendly unit that abstracts tokens, minutes, and mixed workloads.
- Outcome-based pricing when you can measure lift cleanly and both sides can verify results without endless debates.
The trap is pretending there’s a perfect model on day one. In fact, 95% of AI startups misprice their offerings and iterate pricing to align with value. AI pricing usually needs a pilot period because it’s easy to misjudge what customers will actually use and what it costs you to deliver.
Next, we’ll break down each model, what it’s best at, and where it tends to break.
Why Hybrid Subscription + Usage Wins for AI Features
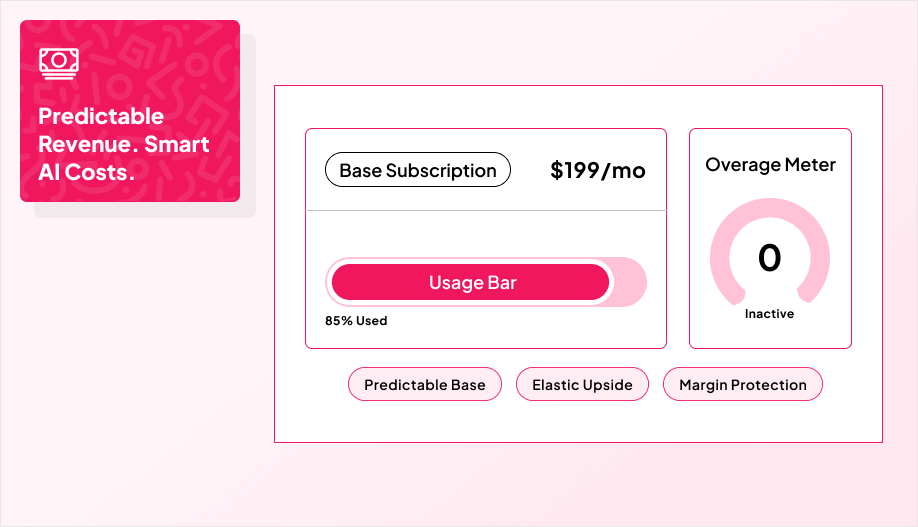
Hybrid pricing works because it matches how AI behaves in the real world.
Your costs track tokens, API calls, and compute time. A flat subscription looks “simple” until a handful of power users quietly turn your margin into a donation. Pure usage pricing has the opposite problem and that is it being fair on paper, but it makes budgets feel slippery, which slows adoption and creates churn the moment customers get surprised.
A hybrid plan gives you both levers. You charge a recurring base so customers can forecast and procurement can approve, then you meter the heavy lift so cost-to-serve stays aligned with revenue.
At the same time, subscription-only models are projected to decline by 5% over the next year. That’s also why a lot of teams are tightening free usage, adding rate limits, and moving advanced AI capabilities into paid tiers. Hybrid models have been gaining share in SaaS as companies blend predictable subscriptions with usage elements that scale with consumption.
Here are the three hybrid structures that show up the most:
| Hybrid Structure | How It Works | Best Fit |
|---|
| Base + Included Allowance | Fixed monthly fee with a generous included pool; overage keeps things flowing without hard stops. | Mid-market SaaS where customers want predictability but usage varies. |
| Commitment + Usage | A committed spend covers baseline costs, then usage kicks in for spikes. | Enterprise contracts, where you need cost coverage and elasticity. |
| Per-Seat + Pooled Allowance | Seats scale the plan, but usage draws down from a shared pool, with soft caps to prevent runaway spend. | Teams adopting AI across departments without wanting per-user chaos. |
Two practical notes that keep hybrid from backfiring:
- Make the allowance feel meaningful. If customers hit overage in week one, they’ll call it a bait-and-switch.
- Put guardrails where the cost is. Rate limits, caps, and “this tier includes X, not Y” boundaries matter more than clever price pages.
If you want to pressure-test the tiers and meters before you ship them, that’s the kind of product + billing work our team at AppMakers USA can help with, especially when AI features sit inside a larger roadmap and you need pricing that won’t collapse under real usage.
Why Credits Beat Tokens for Customer-Friendly AI Pricing
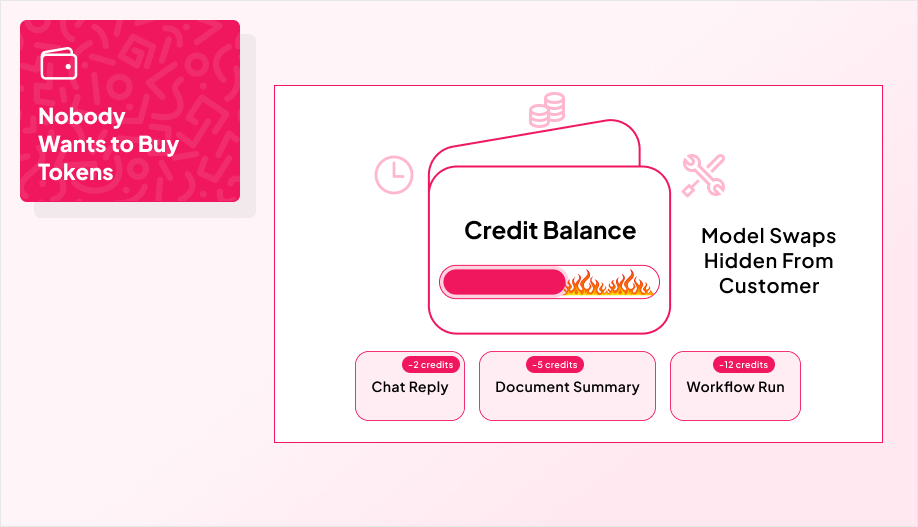
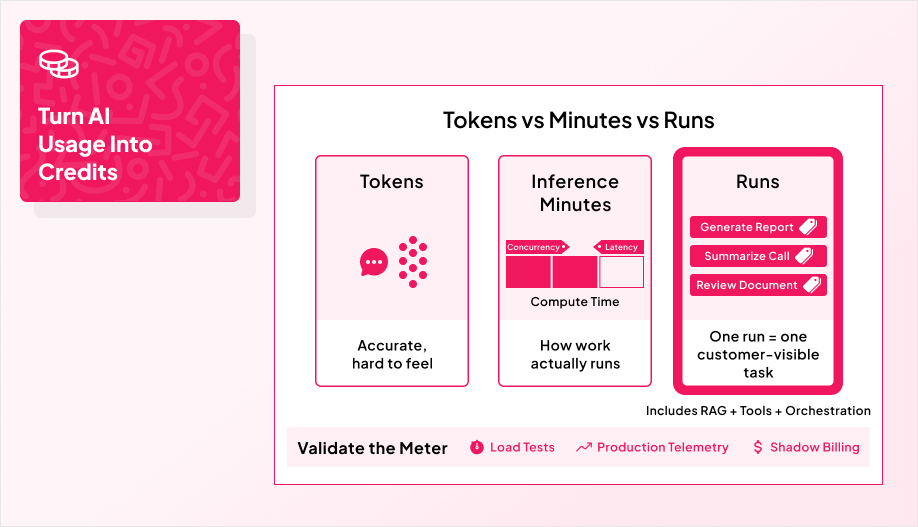
Credits exist because nobody wants to buy tokens.
Most customers do not care about GPU minutes, model swaps, or whether a workflow used chat, embeddings, and file analysis under the hood. They care about two things: “How much is this going to cost me?” and “What do I get for it?”
A prepaid wallet with credits answers both. You sell an abstract unit, fund the wallet up front, and burn credits per action instead of per token. That keeps the pricing anchored to the work the customer recognizes, while giving you room to change models, routing, or infrastructure without rewriting your entire price page.
This is why credit wallets keep showing up in AI products. They simplify the buying experience and make budgets feel stable even when underlying costs bounce around.
On your side, you get earlier cash, cleaner forecasts, and fewer billing disputes because usage is capped by the wallet balance. On the customer side, they get hard spend limits, visibility into remaining balance, and safe room to experiment without getting ambushed by an invoice.
The key is to design credits like a product, not a billing hack.
Define the credit using both a cost model and a value model. Set clear burn rules per action, bundle packs so common workflows can be completed multiple times, and publish the policies that prevent fights later: expiration, refunds, and overage behavior. Then add the basics that make it feel trustworthy in day-to-day use: auto top-ups, low-balance alerts, and real-time dashboards.
This structure is especially clean for agent-based features where a single “task” might involve multiple tool calls and orchestration steps, but the customer still expects one simple unit to pay for.
This is the kind of packaging + metering work AppMakers USA builds alongside the feature itself so pricing does not break once usage gets real.
How to Make Pay-Per-Result Pricing Hold Up
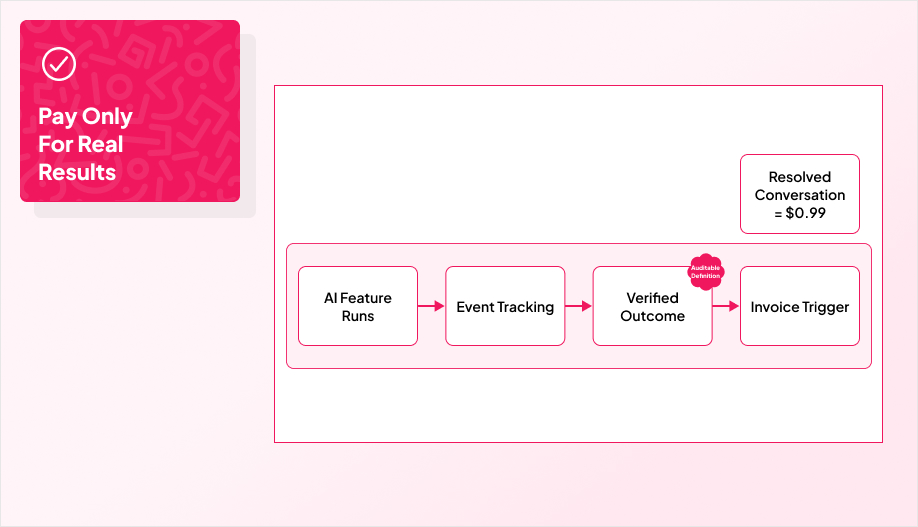
Outcome-based pricing is the cleanest story you can tell a customer: you pay when the result happens, not when the model ran.
Done right, it turns pricing into ROI instead of access, which usually shortens the “is this worth it?” debate and build trust because customers are not paying for effort, they’re paying for an outcome they can see.
A strong real-world example is Intercom’s Fin, which charges $0.99 per resolution. That works because the unit is obvious and the result is measurable.
The hard part is not the price. It’s the proof.
Outcome pricing only holds up if you define the outcome clearly, instrument events end to end, and set attribution rules that survive edge cases and audits. When multiple systems contribute, you need a source of truth, a threshold that counts as “success,” and written rules for disputes, SLAs, and escalation paths. Billing tooling can help operationalize it, but it does not replace the measurement discipline.
Platforms like Lago are built around event-driven usage metering and invoicing, which is the kind of foundation you need when billing is tied to verified events.
If you want this model to work in a real product, the work usually lives in the plumbing data pipelines, event tracking, and contracts that make “what counts” unambiguous. That’s exactly where our team at AppMakers USA tends to step in, because outcome pricing falls apart fast when the instrumentation is fuzzy.