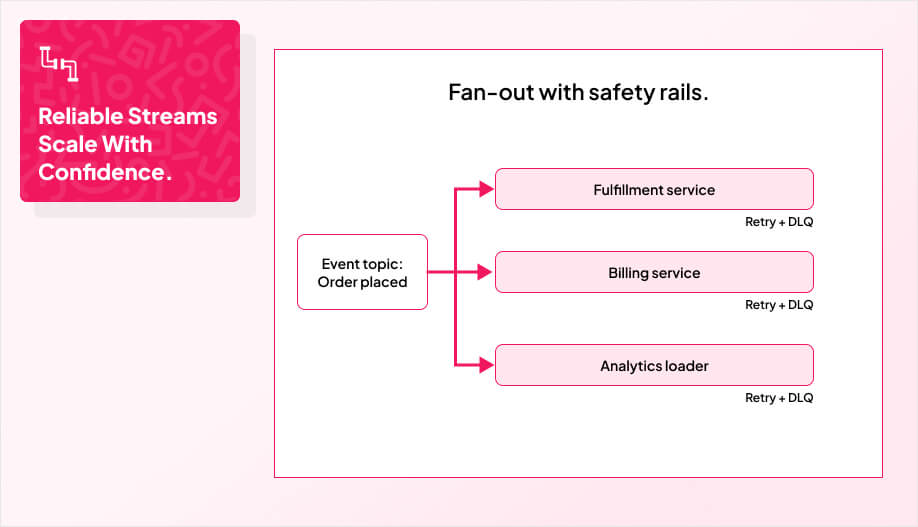
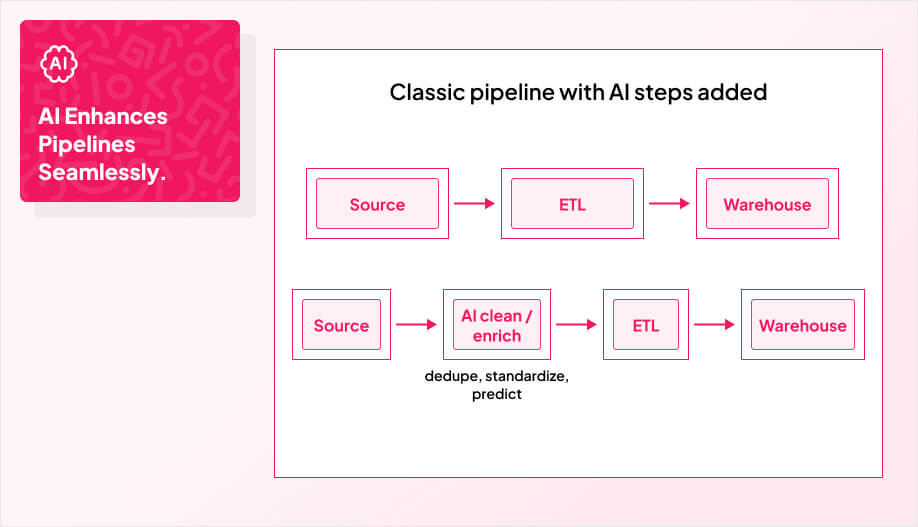
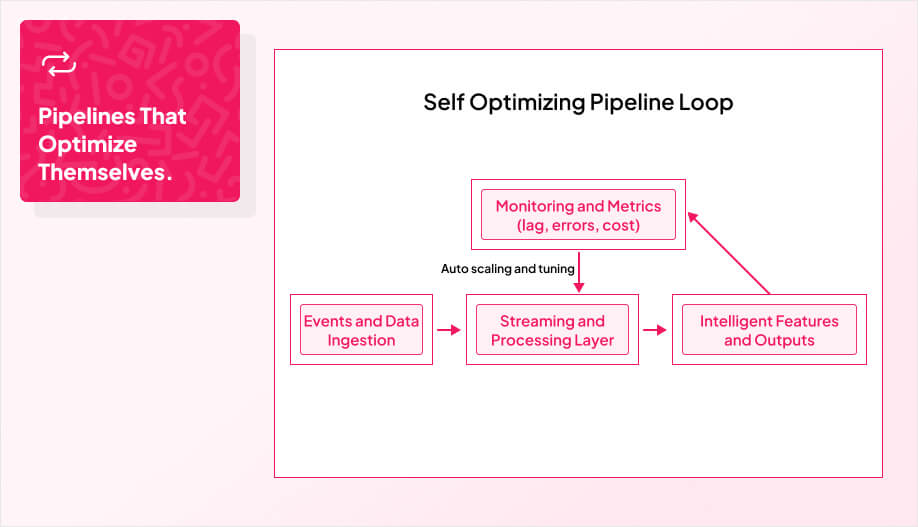
If you want intelligent features to behave reliably, your data needs to be boring: consistent, accurate, and predictable. That does not happen by accident. You lock in clear data quality standards, automate how policies are enforced, and catch anomalies in real time before they affect users.
You start with rigorous data profiling so you understand how your datasets behave in practice: where values are missing, how they drift, where duplicates creep in. You treat these guardrails like part of the pipeline’s design, not an afterthought, so your data stays trustworthy while volume and complexity grow. Grounding these controls in a clear data strategy keeps governance efforts aligned with real business outcomes. That’s why we prioritize automated governance that can keep pace as data volume and complexity scale.
The teams we work at AppMakers USA wire these guardrails in early ship intelligent features faster because they spend less time chasing hidden data problems.
What “Good Data” Actually Means For Your Pipelines
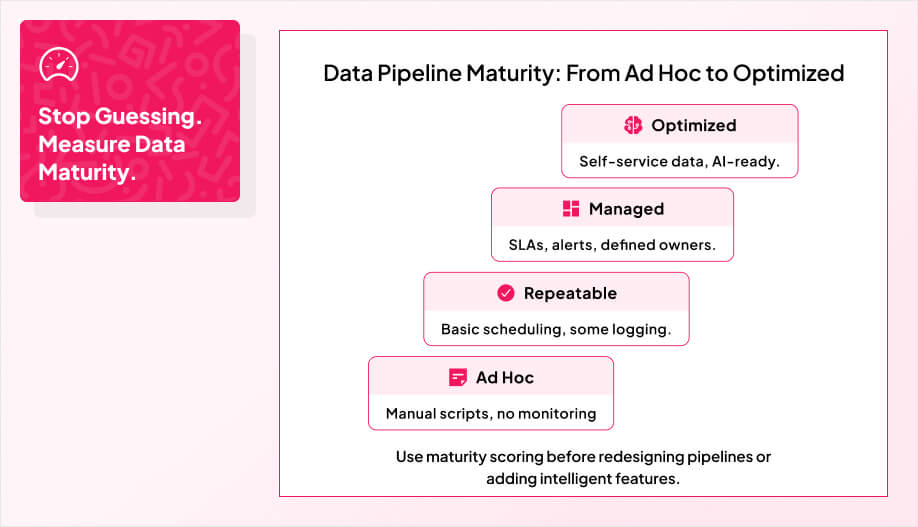
 Before you can trust any pipeline, you need clear data quality standards and governance guardrails that everyone agrees upon and follows. You start by defining what “good data” means for your business: relevance, accuracy, completeness, and timeliness. These standards should explicitly cover key dimensions such as completeness, consistency, and timeliness so they can be monitored and improved over time.
Before you can trust any pipeline, you need clear data quality standards and governance guardrails that everyone agrees upon and follows. You start by defining what “good data” means for your business: relevance, accuracy, completeness, and timeliness. These standards should explicitly cover key dimensions such as completeness, consistency, and timeliness so they can be monitored and improved over time.
Make those dimensions measurable. Set thresholds for accuracy, completeness, and freshness so people know when data is actually usable for intelligent features. Clearly defined data governance roles ensure accountability for monitoring and enforcing these thresholds across teams.
Standardize structure as well as quality: data types, required versus optional fields, valid ranges, and reference values for every critical field. This level of standardization is what enables a single source of truth and makes ongoing audits far more straightforward. Document these in a data quality policy that doubles as the reference for audits and compliance reviews.
On real projects, the turning point is ownership. Once specific people are responsible for specific datasets and thresholds, data quality shifts from being a nice idea to something that is maintained day to day. The AppMakers USA team leans hard on that model, working directly with data owners so these standards show up in everyday workflows instead of sitting in a policy doc.
Automated Governance Policy Enforcement
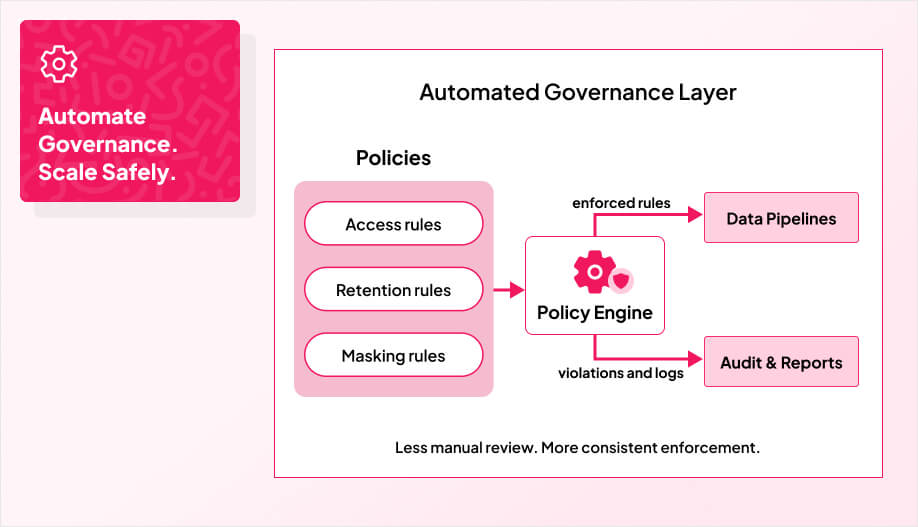 Once you define what “good data” looks like, the only way to keep it that way at scale is to automate how policies are applied and monitored.This includes implementing Active Data Governance to ensure policies are consistently enforced and auditable across all data domains. Our team’s experience delivering end-to-end solutions across multiple sectors shows automation reduces manual errors and speeds enforcement of policies, which is why we embed product roadmaps into governance designs.
Once you define what “good data” looks like, the only way to keep it that way at scale is to automate how policies are applied and monitored.This includes implementing Active Data Governance to ensure policies are consistently enforced and auditable across all data domains. Our team’s experience delivering end-to-end solutions across multiple sectors shows automation reduces manual errors and speeds enforcement of policies, which is why we embed product roadmaps into governance designs.
You centralize rules in a unified policy center, gain single-pane visibility, and stop debating who owns which dataset. A transparent policy center with enforcement analytics helps you monitor compliance rates, policy violations, and the real business impact of your governance rules in real time. From there, you let the system do the heavy lifting. Automated checks block out of policy data from flowing downstream, flag violations, and produce audit trails. Dashboards show compliance rates, top recurring issues, and where policies are too strict or too loose. AI assisted classification can help tag sensitive fields, spot risky access patterns, and surface privacy risks early. Our approach draws on Bespoke software practices to ensure the governance tools match each organization’s needs.
From our AppMakers USA experience, the goal is to make governance feel like guardrails, not handcuffs. A well-defined data governance framework ensures data quality, security, and compliance are managed consistently across the organization while reducing risk and supporting future innovation. It should feel like safety rails, not handcuffs:
- Protect customers’ trust.
- Sleep without compliance anxiety.
- Ship features without second-guessing data.
- Know regulators won’t blindside you.
We design these guardrails to integrate cleanly with your stack today.
Real-Time Anomaly Detection As a Standing Guardrail
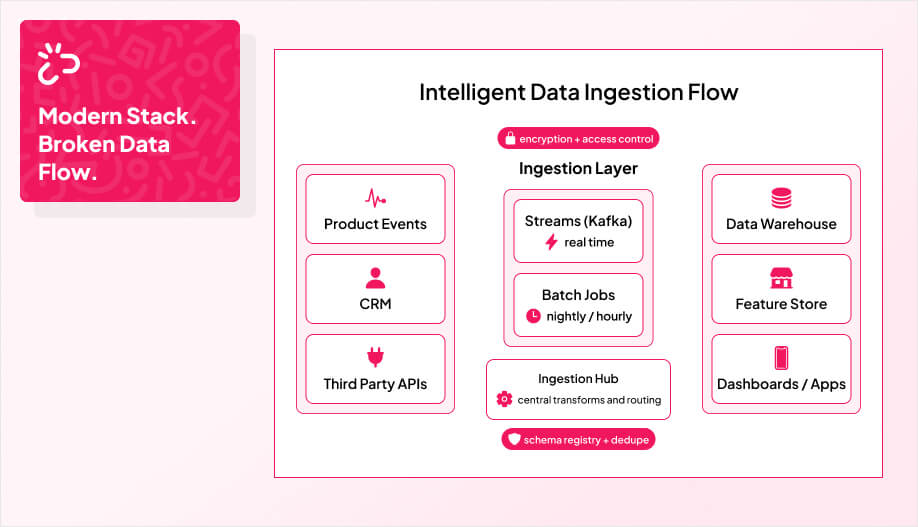
 If your product depends on live data, you cannot wait until tomorrow’s report to discover something broke. Because these systems are built on event-driven architectures, they can handle growing data volumes while still supporting low-latency anomaly detection. Anomaly detection has to be part of the pipeline, watching streams in real time and flagging strange behavior before it hits users or models.
If your product depends on live data, you cannot wait until tomorrow’s report to discover something broke. Because these systems are built on event-driven architectures, they can handle growing data volumes while still supporting low-latency anomaly detection. Anomaly detection has to be part of the pipeline, watching streams in real time and flagging strange behavior before it hits users or models.
In practice, you stream events through a log or message bus, process them with a streaming engine, and apply lightweight algorithms that highlight unusual patterns: sudden spikes, sharp drops, or distributions that no longer match recent history. In our reference implementation, a Kafka-Spark pipeline with Isolation Forest and a Dash dashboard is containerized with Docker Compose to stream synthetic power plant energy data and flag anomalies in real time. Our team also emphasizes building scalable architecture so the pipeline grows with business needs.
The key is to treat anomalies as first class signals. Alerts should route to the right owners, include enough context to debug, and tie back to clear runbooks so incidents do not stall. Over time you tune the rules, retrain models on sliding windows, and scale compute so detection keeps pace with traffic.
Teams that invest in this early usually keep latency in the millisecond to second range and avoid the slow bleed of silent data issues, which has been the pattern across AppMakers USA projects. On Databricks, Delta Live Tables automates ingestion and transformation so real-time anomaly detection pipelines stay reliable with minimal operational overhead. It is cheaper to catch a bad stream in real time than to unwind a week of corrupted model outputs.