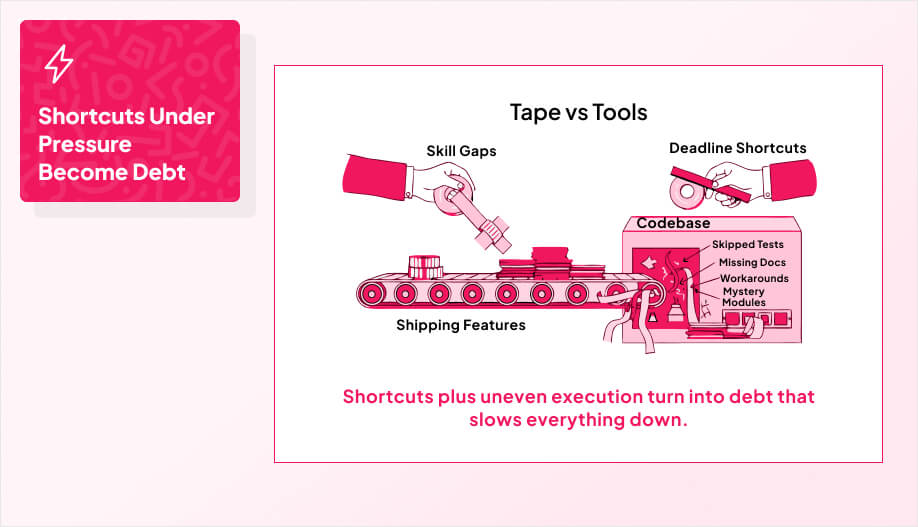
You’ll usually see technical debt first in your delivery friction and your trend lines, long before systems start “breaking.” Stripe’s Developer Coefficient estimated developers spend 42% of their time on maintenance work tied to bad code and related issues, which matches what teams feel when debt starts constraining change.
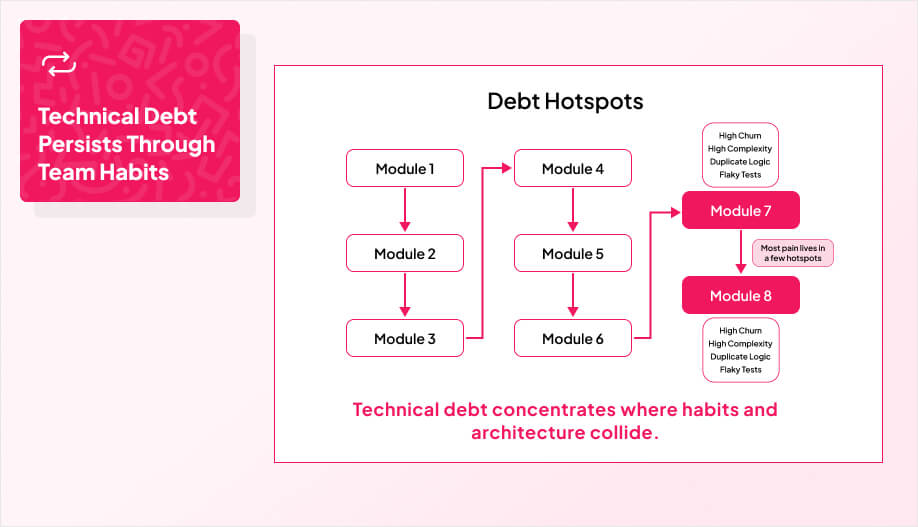
When complexity indicators climb while “simple” work gets slower and riskier, you’re watching the interest kick in. This is also where the 80/20 rule matters. A small set of hotspots tends to cause most of the drag, so you fix those first and stop burning cycles everywhere else.
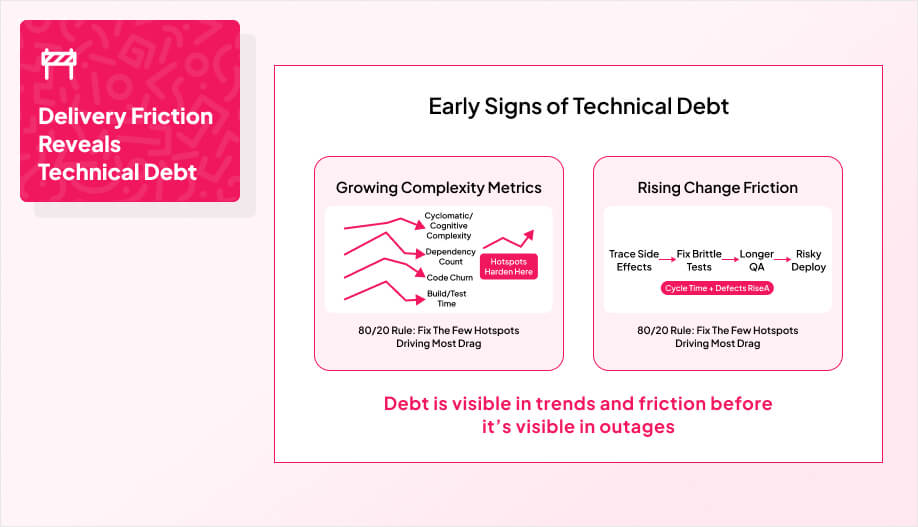
Growing Complexity Metrics
Even before outages or missed deadlines, debt shows up as rising complexity. Cyclomatic and cognitive complexity creep up, code paths multiply, and “safe changes” get rarer. Watch for code churn and volatile files too. If the same areas are constantly touched by multiple people and still feel unstable, that’s a hotspot hardening.
As teams adopt architectures powered by 5G and edge computing, unnoticed complexity in distributed workflows can quickly magnify operational risk. Large files, growing dependency counts, deep inheritance, and high coupling usually mean the design is calcifying into something brittle. Rising build and test latency is another early tell. It slows feedback, stretches cycle time, and makes teams avoid small refactors that would have prevented bigger problems.
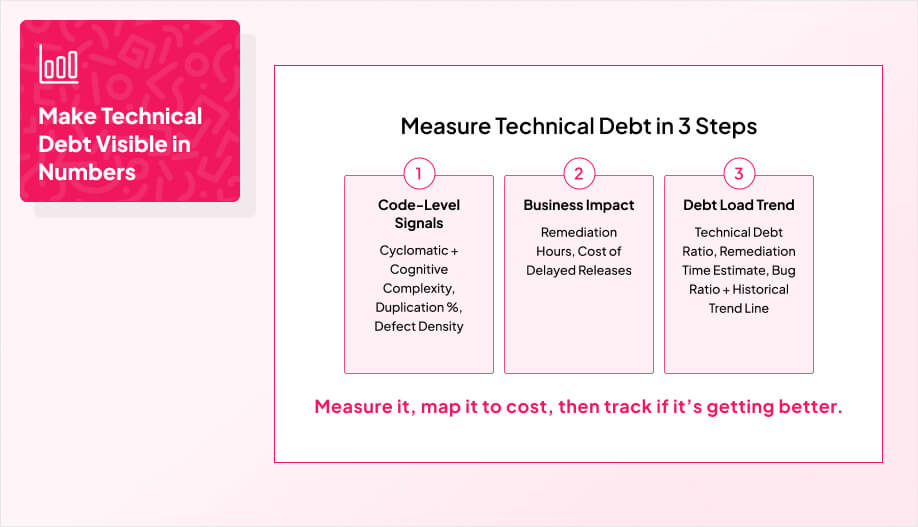
Track a simple Technical Debt Ratio over time so this stays visible in planning, not just in retros. When you tie these signals into an Agile development cadence, remediation becomes part of delivery, not an emergency side quest.
Rising Change Friction
Technical debt stops being theoretical when a one-line tweak takes days. People spend more time tracing side effects, navigating brittle tests, and negotiating code review risk than actually changing behavior. That is a change in friction, and it’s often your clearest signal that alterability is degrading.
Ward Cunningham’s metaphor still holds up in which the “interest” shows up as longer cycle times, growing QA effort, and nervous deployments. Then it gets self-reinforcing.
In a fast-moving Los Angeles tech ecosystem, this kind of drag can quietly erase the advantages of rapid iteration and local market opportunities. Small refactors get postponed, the next change gets harder, and you lose options. Experiments, revenue features, and even compliance updates start costing more than they should.
When that drag becomes normal, it’s time to pay down debt deliberately, starting with the few hotspots driving most of the pain.